

Excel:從混亂信息中提取文字
在今天的數字化時代,Excel已經成為了生活中一個極為重要的軟件,無論是在公司還是在個人生活中,Excel都會被廣泛的使用。然而,在Excel中大量信息的存在下,我們如何從混亂的信息中提取有用的文字呢?
Excel:函數的妙用
如果你掌握了Excel函數的使用,就可以從Excel中輕松提取信息。例如,使用“VLOOKUP”函數可以在Excel表格中查找特定信息并返回相應的結果。此函數可以快速搜索數據表,查找要匹配的值,并返回該行中的結果。
假設我們有一張包含人員信息的表格,并且我們想要根據一個人的姓名來查找他的郵箱地址,可以使用VLOOKUP函數進行查詢,公式如下:
=VLOOKUP(lookup value, table array, column number, FALSE)
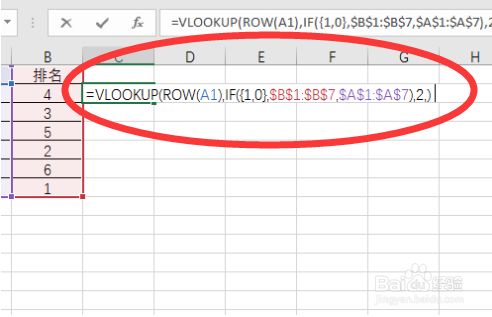
其中,lookup value表示要查找的值(即姓名),table array表示要在哪個表格中進行查找,column number表示要返回的信息所在的列數,FALSE表示要精確匹配。
通過這個簡單的函數公式,我們可以輕松地從Excel表格中提取出有用的信息。
Excel:文本函數
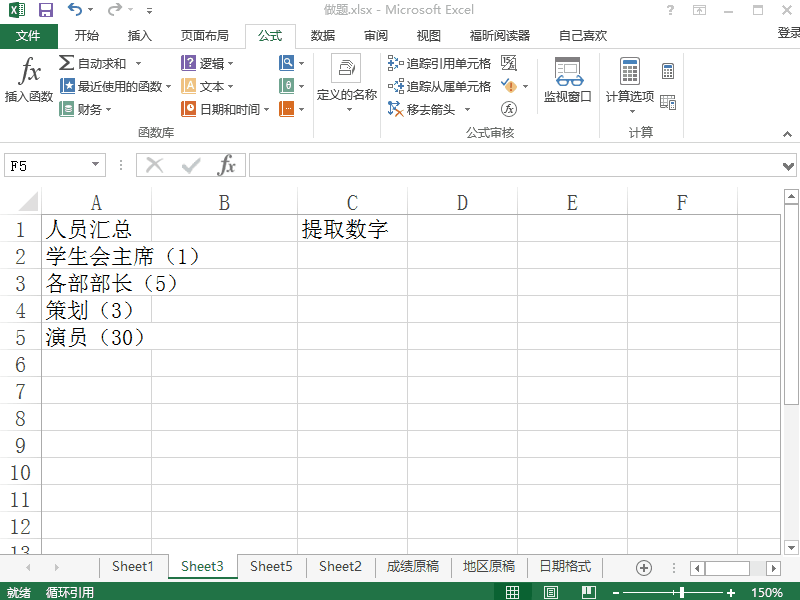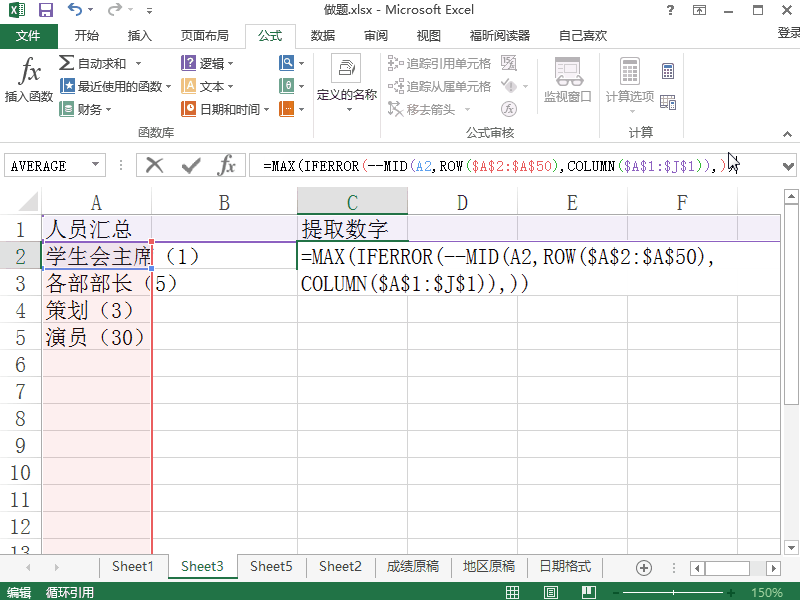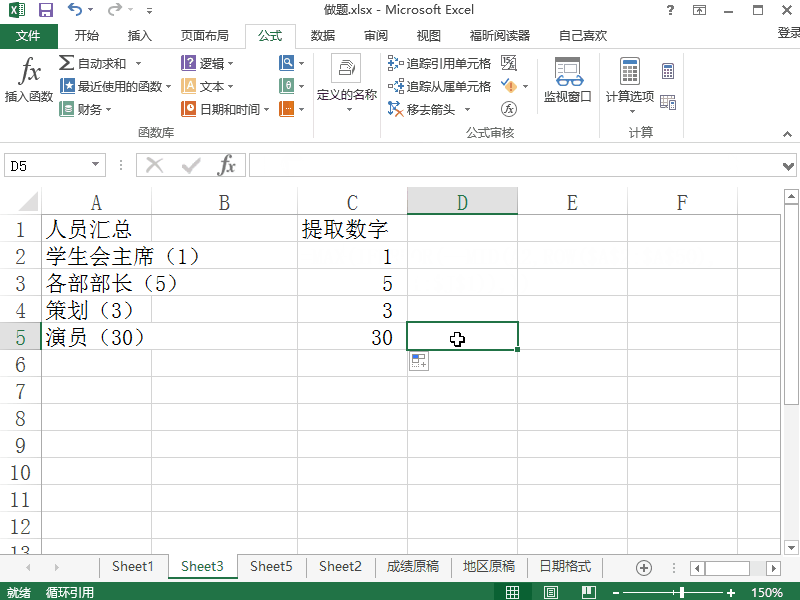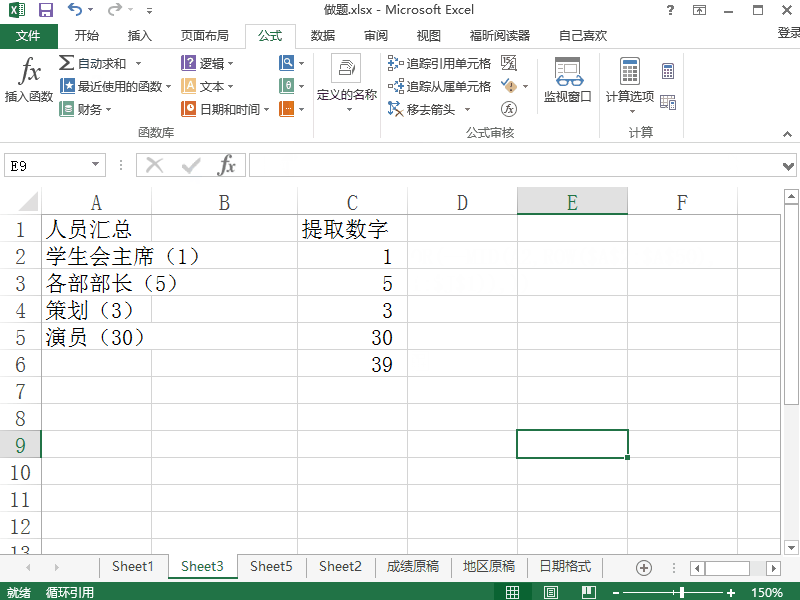
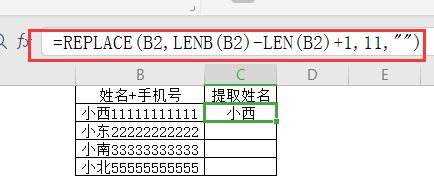
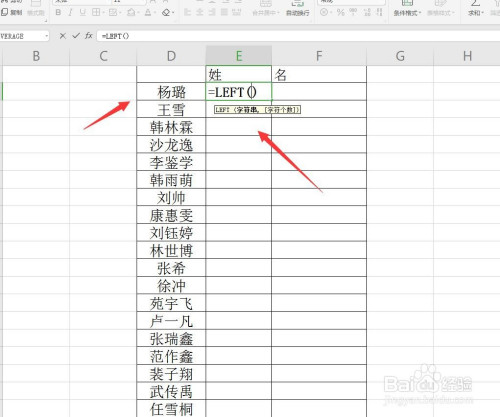
除了常用的函數外,Excel中還有很多文本函數,如“LEFT”、“RIGHT”、“MID”等,這些函數可以根據文本的位置和長度來提取有用的信息。
例如,如果我們要從一列地址中提取出城市名稱和州名稱,我們可以使用“LEFT”和“RIGHT”函數來實現。
公式如下:
=LEFT(text, )
=RIGHT(text, )
其中,text表示要提取信息的文本,表示要提取的字符數。
這些函數可以輕松地在Excel中提取出有用的文本信息,讓數據處理變得更加簡單高效。
Excel:過濾和排序
除了使用函數和文本函數外,在Excel中還可以使用過濾和排序功能來快速提取信息。
在Excel中,可以使用篩選器進行過濾,只顯示我們需要的信息。我們可以按照不同的條件來篩選數據。例如,在一個包含員工姓名、職位和部門的表格中,我們可以使用篩選器來只顯示某個部門的員工信息。
另外,通過排序功能,我們可以快速對數據進行排序,以便更好地查找和分析。例如,在一個銷售記錄表格中,我們可以根據時間將記錄按照日期升序或降序排序,這樣可以更好地查看銷售情況。
Excel:結合姓名學和互聯網素材資料整合信息
除了在Excel中提取信息外,我們還可以結合姓名學和互聯網素材資料中的信息,來對Excel的信息進行整合。
姓名學是通過人名研究來了解一個人的性格、命運和發展等方面的學科,我們可以根據一個人的姓名,來推測出他的性格特點和個人發展趨勢。
而在互聯網素材資料中,我們可以從個人的社交網絡、博客、新聞報道和其他公開信息等來源中,來了解一個人的工作經歷、教育背景、專業技能和興趣愛好等信息。
結合姓名學和互聯網素材資料,我們可以更全面地了解一個人,并從Excel中提取出更加有用的信息。
總結
在Excel中提取信息是一個非常重要的工作,可以讓我們更好地了解數據和發現隱藏在數據中的規律。通過掌握Excel函數、文本函數、過濾和排序、姓名學和互聯網素材資料整合等技巧,我們可以輕松地從混亂的信息中提取有用的文字。希望這篇文章能夠對大家有所幫助,并在Excel的使用中取得更好的效果。
什么是混亂文本
混亂文本(garbled text)是指一些電子文本在傳輸過程中,由于某些原因(如網絡故障、編碼不一致等),導致文本中出現亂碼、錯碼、重復、丟失等問題,從而讓文本的句意不夠清晰。因此,需要通過某種方法處理這些混亂文本,使其能夠被正確解析。
混亂文本中的數字提取方法
處理混亂文本中的數字,一般可以采用基于規則的方法、基于機器學習的方法或者基于深度學習的方法。其中,基于規則的方法相對簡單,適用于具有明確規律和較少噪聲的數字提取任務。基于機器學習的方法需要先對數據進行標記和模型訓練,但是對于沒有明確規律且噪聲較多的數字提取任務來說,其效果要好于基于規則的方法。基于深度學習的方法在大量數據集的訓練下,可以達到很高的精度,但需要在計算資源和時間成本上付出更多的代價。
姓名學與數字提取
姓名學是一門研究人名和個人命運關系的學說,認為名字與人的性格、職業、行為等方面存在著一定的聯系。在數字提取上,姓名學能夠幫助分析姓名和數字之間的關系,從而更加準確地提取數字。
例如,“王小明”的姓名學分析結果有:“王”字代表權威、穩健,數字1、2、3、4 的位權分別為10000、1000、100、10、1,而“小明”則代表靈敏、智慧、開朗,數字4、6、8、9 的位權分別為10000、1000、100、10、1。因此,在分析這個姓名時,如果文本中出現了1、2、3、4、6、8、9這幾個數字,可以將其優先選取。
互聯網素材資料與數字提取
在互聯網的時代,幾乎所有的企業、個人、機構都有自己的網站、微信公眾號、APP等互聯網媒體作為宣傳和交流的渠道,這些媒體中都會包含一些數字化信息。因此,在數字提取領域,互聯網素材資料的應用非常廣泛,可以通過網絡爬蟲、API接口等方法獲取到相關數字信息。
舉個例子,假設我們需要從某公司網站上獲取最新股票價格,我們可以通過爬蟲技術獲取網站上有關股票的HTML源碼,然后通過對源碼進行解析,找到對應的字符位置,從中提取出數字信息。此外,一些互聯網公司也會提供開放API接口,以供用戶獲取相關數字信息。在這種方式下,我們只需向開發者申請API密鑰,然后將密鑰傳入API請求中,即可從服務器響應中獲取到想要的數字信息。