

聊聊慢SQL中關(guān)于IN語法的優(yōu)化分析過程。
技術(shù)人人都可以磨煉,但處理問題的思路和角度各有不同,希望這篇文章可以拋磚引玉。
以一個(gè)例子為切入點(diǎn)
一、問題背景
某業(yè)務(wù)模塊反饋SQL慢,優(yōu)化過程中的一些思考做個(gè)記錄。
基礎(chǔ)環(huán)境:
問題現(xiàn)象:慢SQL
簡(jiǎn)單說明:
在很多應(yīng)用場(chǎng)景中,SQL 的性能直接決定了系統(tǒng)的性能。此外,查詢速度慢并不只是因?yàn)?SQL 語句本身,還可能是因?yàn)閮?nèi)存分配不佳、文件結(jié)構(gòu)不合理、刷臟頁等其他原因。
本文介紹一些通過調(diào)整 SQL 語句就能優(yōu)化SQL的通用小技巧,優(yōu)化 SQL 的方法不能解決所有的性能問題,但是卻能處理很多因 SQL 寫法不合理而產(chǎn)生的性能問題。
二、分析說明
三、疑問點(diǎn)排查及分析思路

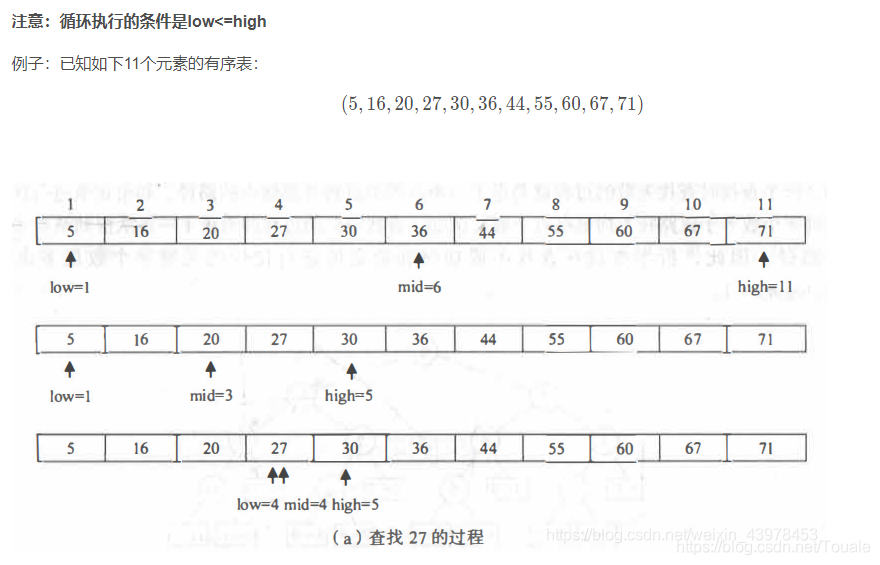
原SQL結(jié)構(gòu)如下:
*
FROM tab_a
WHERE ID IN ( c_id FROM tab_b);
業(yè)務(wù)需求我看了一下in子查詢數(shù)據(jù)庫怎么用,還真不能怪開發(fā)小哥這么寫,我第一反應(yīng)也是這么寫,用IN的好處就是SQL比較直觀,容易理解SQL邏輯。
1、IN語法的SQL執(zhí)行計(jì)劃
SQL如下:
*
FROM tab_a
WHERE ID IN ( c_id FROM tab_b);

執(zhí)行計(jì)劃如下:
就這個(gè)SQL的執(zhí)行計(jì)劃本身來說還是不錯(cuò)的(MySQL查詢轉(zhuǎn)換做的不錯(cuò)),我想說的主要關(guān)注點(diǎn)在(tab_a)上。
我們看到上面查詢計(jì)劃中,extra列可以看到 (tab_a) 。MySQL使用了連接來處理此查詢,對(duì)于tab_a表的行,只要能在tab_b表中找到1條滿足即可以不必再檢索tab_a表。從語義角度來看,和IN-to-EXIST策略轉(zhuǎn)換為Exist子句是相似的,區(qū)別就是以連接形式執(zhí)行查詢,而不是子查詢。
策略背后的思想和in->轉(zhuǎn)換思想相同。有以下的優(yōu)點(diǎn):
策略意味著子查詢的表必須在父查詢中的表之后被引用,支持相關(guān)子查詢;不能應(yīng)用于子查詢帶有g(shù)roup by或聚合函數(shù)的場(chǎng)景。
PS:是否開啟是由系統(tǒng)變量中的=on|off設(shè)置的。
2、語法的SQL執(zhí)行計(jì)劃
SQL如下:
a.*
FROM tab_a a
WHERE ( c_id FROM tab_b b where a.id=b.c_id);
執(zhí)行計(jì)劃如下:
通常來講, 比 IN 更快的原因有兩個(gè):
針對(duì)某一個(gè)查詢,有時(shí)候會(huì)有多種 SQL 實(shí)現(xiàn),例如 IN、、連接之間的互相轉(zhuǎn)換。從理論上來講,得到相同結(jié)果的不同 SQL 語句應(yīng)該有相同的性能,但遺憾的是,查詢優(yōu)化器生成的執(zhí)行計(jì)劃很大程度上要受到外部結(jié)構(gòu)的影響。
因此,如果想優(yōu)化查詢性能,必須知道如何寫 SQL 語句才能使優(yōu)化器生成更高效的執(zhí)行計(jì)劃。
3、使用代替IN是否更好?
如果 IN 的參數(shù)是 1,2,3 這樣的數(shù)值列表,一般還不需要特別注意,但如果參數(shù)是子查詢,那么就需要注意了;在大多時(shí)候, [NOT] IN 和 [NOT] 返回的結(jié)果是相同的,但是兩者用于子查詢時(shí), 的速度會(huì)更快一些。
當(dāng) IN 的參數(shù)是子查詢時(shí),數(shù)據(jù)庫有可能首先會(huì)執(zhí)行子查詢(上述分析案例不是),然后將結(jié)果存儲(chǔ)在一張臨時(shí)表里(內(nèi)聯(lián)視圖),然后掃描整個(gè)視圖,很多情況下這種做法非常耗費(fèi)資源。而使用 的話,數(shù)據(jù)庫不會(huì)生成臨時(shí)表。
減少臨時(shí)表也是在 SQL優(yōu)化中需要注意的點(diǎn),子查詢的結(jié)果會(huì)被看成一張新表(臨時(shí)表),這張新表與原始表一樣,可以通過 SQL 進(jìn)行操作。但是頻繁使用臨時(shí)表會(huì)帶來兩個(gè)問題:

因此,盡量減少臨時(shí)表的使用也是提升性能的一個(gè)重要方法。
4、其他代替IN的方案
其實(shí)在平時(shí)工作當(dāng)中,更多的是用連接代替 IN 來改善查詢性能,而非 ,不是說連接更好,而是 很難掌握(SQL邏輯不夠直白)。
剛剛的SQL,如果用連接來實(shí)現(xiàn),如何寫?
SQL如下:
a.*
FROM tab_b b left join tab_a a on b.c_id=a.id
執(zhí)行計(jì)劃如下:
這種寫法能充分利用索引;而且因?yàn)闆]有了子查詢,所以數(shù)據(jù)庫也不會(huì)生成中間表;所以,查詢效率還是不錯(cuò)的。至于 JOIN 與 相比哪個(gè)性能更好,不太好說;如果沒有索引,可能 會(huì)略勝一籌,有索引的話,兩者差不多。
執(zhí)行計(jì)劃里需要注意的一個(gè)點(diǎn)是Using , 表示進(jìn)行了排序或分組,顯然這個(gè) SQL 沒有進(jìn)行分組,而是進(jìn)行了排序運(yùn)算。
為了排除重復(fù)數(shù)據(jù), 也會(huì)進(jìn)行排序,而排序操作一般是要避免的,怎么避免?
5、使用 代替
還是剛剛的SQL,如果不用 過濾數(shù)據(jù),怎么寫?
用 來進(jìn)行優(yōu)化
可以看到in子查詢數(shù)據(jù)庫怎么用,已經(jīng)規(guī)避了排序運(yùn)算。
總結(jié)
文中雖然列舉了幾個(gè)要點(diǎn),但其實(shí)優(yōu)化的核心思想只有一個(gè),那就是找出性能瓶頸所在,然后解決它。不管是減少排序還是使用索引,亦或是避免臨時(shí)表的使用,其本質(zhì)都是為了減少對(duì)硬盤的訪問。
小技巧:
覺得本文有用,請(qǐng)轉(zhuǎn)發(fā)、點(diǎn)贊或點(diǎn)擊“在看”聚焦技術(shù)與人文,分享干貨,共同成長(zhǎng)更多內(nèi)容請(qǐng)關(guān)注“數(shù)據(jù)與人”