

開始我是很難弄懂什么是過擬合機器學習防止過擬合,什么是欠擬合以及造成兩者的各自原因以及相應的解決辦法,學習了一段時間機器學習和深度學習后,分享下自己的觀點,方便初學者能很好很形象地理解上面的問題,同時如果有誤的地方希望大家在評論區留下你們的磚頭,我會進行糾正。
無論在機器學習還是深度學習建模當中都可能會遇到兩種最常見結果,一種叫過擬合(over- )另外一種叫欠擬合(under-)。
首先談談什么是過擬合呢?什么又是欠擬合呢?網上很直接的圖片理解如下:
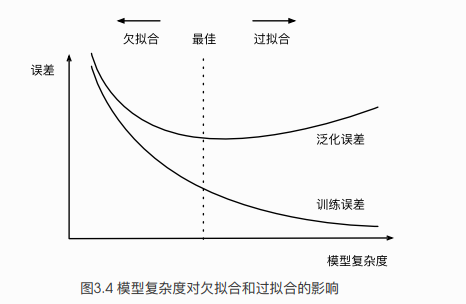
所謂過擬合(over-)其實就是所建的機器學習模型或者是深度學習模型在訓練樣本中表現得過于優越,導致在驗證數據集以及測試數據集中表現不佳。打個比喻就是當我需要建立好一個模型之后,比如是識別一只狗狗的模型,我需要對這個模型進行訓練。恰好,我訓練樣本中的所有訓練圖片都是二哈,那么經過多次迭代訓練之后,模型訓練好了,并且在訓練集中表現得很好。基本上二哈身上的所有特點都涵括進去,那么問題來了!假如我的測試樣本是一只金毛呢?將一只金毛的測試樣本放進這個識別狗狗的模型中,很有可能模型最后輸出的結果就是金毛不是一條狗(因為這個模型基本上是按照二哈的特征去打造的)。所以這樣就造成了模型過擬合,雖然在訓練集上表現得很好,但是在測試集中表現得恰好相反,在性能的角度上講就是協方差過大( is large),同樣在測試集上的損失函數(cost )會表現得很大。
所謂欠擬合呢(under-)?相對過擬合欠擬合還是比較容易理解。還是拿剛才的模型來說,可能二哈被提取的特征比較少,導致訓練出來的模型不能很好地匹配,表現得很差,甚至二哈都無法識別。

那么問題來了,我們需要怎么去解決過擬合和欠擬合的問題呢??
過擬合:
首先我們從上面我們可以知道,造成過擬合的原因有可以歸結為:參數過多。那么我們需要做的事情就是減少參數,這里有兩種辦法:

1、回想下我們的模型,假如我們采用梯度下降算法將模型中的損失函數不斷減少,那么最終我們會在一定范圍內求出最優解,最后損失函數不斷趨近0。那么我們可以在所定義的損失函數后面加入一項永不為0的部分,那么最后經過不斷優化損失函數還是會存在。其實這就是所謂的“正則化”。
下面這張圖片就是加入了正則化()之后的損失函數。這里m是樣本數目,landa(后面我用“t”表示,實在是打不出)表示的是正則化系數。
注意:當t(landa)過大時,則會導致后面部分權重比加大,那么最終損失函數過大,從而導致欠擬合

當t(landa)過小時,甚至為0,導致過擬合。
2、對于神經網絡,參數膨脹原因可能是因為隨著網路深度的增加,同時參數也不斷增加,并且增加速度、規模都很大。那么可以采取減少神經網絡規模(深度)的方法。也可以用一種叫的方法。的思想是當一組參數經過某一層神經元的時候機器學習防止過擬合,去掉這一層上的一部分神經元,讓參數只經過一部分神經元進行計算。注意這里的去掉并不是真正意義上的去除,只是讓參數不經過一部分神經元計算而已。

另外增大訓練樣本規模同樣也可以防止過擬合。
欠擬合:
其實個人覺得欠擬合基本上都會發生在訓練剛開始的時候,經過不斷訓練之后欠擬合應該不怎么考慮了。。但是如果真的還是存在的話,可以通過增加網絡復雜度或者在模型中增加多點特征點,這些都是很好解決欠擬合的方法。