

相信每個人都對驗證碼沒有好感——你必須輸入圖像里的文本,然后才能訪問網(wǎng)站。驗證碼的設(shè)計是為了防止計算機自動填寫表格,以此驗證你是一個真實的人。但隨著深度學習和計算機視覺的興起,它們現(xiàn)在已經(jīng)變得脆弱不堪。
我一直在讀一本由 寫的《Deep for with 》(用實現(xiàn)機器視覺的深度學習)。在這本書中,通過機器學習,在E-ZPass紐約網(wǎng)站上繞過了驗證碼階段:
沒有訪問生成驗證碼圖像的應(yīng)用程序的源代碼。為了打破這個系統(tǒng),他不得不下載數(shù)百個示例圖像,并手動輸入每個圖像對應(yīng)的驗證碼來訓練他的系統(tǒng)。
但是,如果我們想要破壞一個開源的驗證碼系統(tǒng),在哪里我們可以訪問源代碼呢?
我在網(wǎng)站(一個插件下載網(wǎng)站)上搜索了“”。網(wǎng)頁置頂?shù)乃阉鹘Y(jié)果為“ ”(“真正簡單的驗證碼”,一個驗證碼生成插件),其活躍安裝次數(shù)超過100萬:
最棒的是,我們可以利用它獲得生成驗證碼的源代碼,所以這應(yīng)該很容易被打破。為了使任務(wù)更有挑戰(zhàn)性,我決定給自己一個時間限制。15分鐘內(nèi),能否徹底破解這個驗證碼系統(tǒng)?擦亮眼睛看吧!
重要提示:這絕不是對該插件或其作者的挑釁或某種程度上的鄙視。插件作者自己也說它已經(jīng)不安全了,建議你使用其他東西。這只是一個有趣和快速的技術(shù)挑戰(zhàn),但如果你是其100萬用戶之一,或許你應(yīng)該換一個插件了:)
挑戰(zhàn)開始
為方便定制攻擊計劃,我們首先看一下該插件會生成什么樣的圖像。在演示網(wǎng)站上,我們看到:
驗證碼圖像展示
從圖像看來,驗證碼明顯是四個字母,不過我們要在PHP源代碼中驗證這一點:
是的,它使用4種不同字體的隨機組合生成4個字母的驗證碼。我們可以看到,在代碼中它從不使用“O”或“I”,以避免用戶混淆。這就給我們留下了32個可能的字母和數(shù)字。

目前記時:2分鐘
我們的工具集
在我們進一步討論之前,先來羅列一下解決這個問題的工具:
3
是一種很有趣的編程語言,有很好的機器學習和計算機視覺庫。
是一個流行的計算機視覺和圖像處理框架。我們將使用來處理驗證碼圖像。它有一個 API,所以我們可以直接從中使用它。
Keras
Keras是一個用編寫的深度學習框架。它能夠以最少的代碼定義、訓練和使用深度神經(jīng)網(wǎng)絡(luò)。(這個評價可能不夠客觀。)
是谷歌的機器學習庫。我們會在Keras中編碼,但是Keras并沒有真正實現(xiàn)神經(jīng)網(wǎng)絡(luò)邏輯本身。因此,它使用谷歌的庫來完成繁重的任務(wù)。
好的,回到挑戰(zhàn)!
創(chuàng)建數(shù)據(jù)集
訓練任何機器學習系統(tǒng),我們都需要訓練數(shù)據(jù)。要破解驗證碼系統(tǒng),我們需要這樣的訓練數(shù)據(jù):

因為我們有了該插件的源代碼,所以我們可以通過修改它來保存10000個驗證圖像,以及每個圖像的預(yù)期答案。
在對代碼進行了幾分鐘的黑客攻擊并添加了一個簡單的for循環(huán)之后,我有了一個包含訓練數(shù)據(jù)的文件夾—10,000個PNG文件易語言網(wǎng)頁驗證碼點擊,每個文件都有正確的答案作為文件名:
目前記時:5分鐘
簡化這個問題
現(xiàn)在我們有了訓練數(shù)據(jù),我們可以直接用它來訓練神經(jīng)網(wǎng)絡(luò):
如果有足夠的訓練數(shù)據(jù),這種方法甚至可能直接產(chǎn)生效果——但我們要使問題變得更簡單。問題越簡單,訓練數(shù)據(jù)越少,我們解決它所需的計算能力就越小。畢竟只有15分鐘!
幸運的是,驗證碼圖像通常只由四個字母組成。如果我們能把圖像分割開來,這樣每個字母都是一個單獨的圖像,那么我們只需訓練神經(jīng)網(wǎng)絡(luò)一次識別單個字母:
我沒有時間去挨個查看10000個訓練圖像,然后用將它們手工分割成不同的圖像。這需要幾天的時間,我只剩下10分鐘了。我們不能將圖像分割成4個等分大小的塊因為驗證碼隨機將字母放置在不同的水平位置,以防止出現(xiàn)這樣的情況:
每個圖像中的字母都是隨機放置的,使圖像分割變得更加困難。
幸運的是易語言網(wǎng)頁驗證碼點擊,我們?nèi)匀豢梢詫崿F(xiàn)自動化。在圖像處理中,我們經(jīng)常需要檢測具有相同顏色的像素的“blob”。這些連續(xù)像素點的邊界稱為輪廓。有一個內(nèi)置的()函數(shù),我們可以用來檢測這些連續(xù)區(qū)域。
我們將從一個原始的驗證碼圖像開始:
然后我們將圖像轉(zhuǎn)換成純黑和白(這稱為閾值化),這樣就很容易找到連續(xù)區(qū)域:
接下來,我們將使用的()函數(shù)來檢測圖像中包含相同顏色連續(xù)的像素點的圖像的不同部分:
然后這就變成了一個簡單的問題,可以把每個區(qū)域作為一個單獨的圖像文件保存。因為我們知道每個圖像應(yīng)該包含四個從左到右的字母,所以我們可以用這些知識來標記我們保存的字母。只要我們按這個順序把它們存起來,應(yīng)該就可以用正確的字母名稱來保存每一個圖像字母。
但是等一下——我發(fā)現(xiàn)問題了!有時驗證碼有這樣重疊的字母:
這意味著我們最終會將兩個字母組合成一個區(qū)域。
如果我們不處理這個問題,我們就會產(chǎn)生“很臟”(dirty)的訓練數(shù)據(jù)。我們需要解決這個問題,防止機器接受訓練后仍然靠運氣識別這兩個重疊在一起的字母。
這里有一個簡單的竅門:如果一個等高線區(qū)域比它的高度寬得多,那就意味著可能有兩個字母在一起被壓扁了。在這種情況下,我們可以把這兩個字母放在中間,把它分成兩個獨立的字母:
我們將把比它們高得多的區(qū)域分割成兩半,把它看成兩個字母。這里有黑客行事風格的嫌疑,但是對于驗證碼來說,它是可行的。
現(xiàn)在我們有了一種提取單個字母的方法,接下來在所有的驗證碼圖像中運行這個方法。目的是收集每個字母的不同變體。我們可以把每個字母都保存在自己的文件夾里,井井有條。
這是我摘取所有字母后的“W”文件夾的圖像:
從我們的10,000個驗證碼圖像中提取的一些“W”字母。我最終得到了1,147個不同的“W”圖像。
目前記時:10分鐘
建立和訓練神經(jīng)網(wǎng)絡(luò)
因為我們只需要識別單個字母和數(shù)字的圖像,我們就不需要一個非常復(fù)雜的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。識別字母比識別像貓和狗這樣的復(fù)雜圖像要容易得多。
我們將使用一個簡單的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),它有兩個卷積層和兩個完全連通的層:
如果你想知道更多關(guān)于卷積神經(jīng)網(wǎng)絡(luò)的工作原理以及為什么它們是圖像識別的理想方法,請查閱的書。
定義這個神經(jīng)網(wǎng)絡(luò)體系結(jié)構(gòu)只需要使用Keras的幾行代碼:
#k!model=()# .add((20,(5,5),="same",=(20,20,1),="relu"))model.add((=(2,2),=(2,2)))# .add((50,(5,5),="same",="relu"))model.add((=(2,2),=(2,2)))#.add(())model.add(Dense(500,="relu"))#es(tter/)model.add(Dense(32,=""))#pile(loss="ropy",="adam",=[""])

現(xiàn)在我們可以訓練它了!
#.fit(,,=(,),=32,=10,=1)
經(jīng)過訓練數(shù)據(jù)集10次之后,我們達到了接近100%的準確度。在這一點上,我們應(yīng)該能夠在我們想要的時候自動繞過這個驗證碼!我們做到了!
計時結(jié)束:15分鐘。
使用訓練的模型來求解驗證碼
現(xiàn)在我們有了一個訓練有素的神經(jīng)網(wǎng)絡(luò),用它來破壞一個真正的驗證碼是很簡單的:
從一個使用該插件的網(wǎng)站上獲取一個真正的驗證碼圖像。
用我們用來創(chuàng)建訓練數(shù)據(jù)集的方法將該圖像分割成四個不同的字母圖像。
讓我們的神經(jīng)網(wǎng)絡(luò)對每個字母圖像做一個單獨的預(yù)測。
用四個預(yù)測字母作為驗證碼的答案。
狂歡接踵而來!
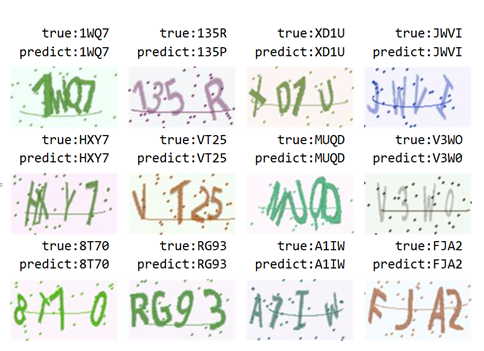
下面是我們的模型如何解碼真實的驗證碼:
或從命令行來看:
試一下!
如果你想親自嘗試,可以在原文中獲取代碼。文件中包括10,000個示例圖像和本文中每個步驟的所有代碼。查看.md文件,可閱讀運行說明。