

光學(xué)文字識(shí)別
光學(xué)文字識(shí)別 即OCR ( )是指電子設(shè)備(例如掃描儀或數(shù)碼相機(jī))檢查紙上打印的字符,通過檢測暗、亮的模式確定其形狀,然后用字符識(shí)別方法將形狀翻譯成計(jì)算機(jī)文字的過程;即,對(duì)文本資料進(jìn)行掃描,然后對(duì)圖像文件進(jìn)行分析處理,獲取文字及版面信息的過程。如何除錯(cuò)或利用輔助信息提高識(shí)別正確率,是OCR最重要的課題,ICR( )的名詞也因此而產(chǎn)生。衡量一個(gè)OCR系統(tǒng)性能好壞的主要指標(biāo)有:拒識(shí)率、誤識(shí)率、識(shí)別速度、用戶界面的友好性,產(chǎn)品的穩(wěn)定性,易用性及可行性等。
光學(xué)文字識(shí)別的概念是在1929年由德國科學(xué)家最先提出來的,后來美國科學(xué)家也提出了利用技術(shù)對(duì)文字進(jìn)行識(shí)別的想法。而最早對(duì)印刷體漢字識(shí)別進(jìn)行研究的是IBM公司的Casey和Nagy,1966年他們發(fā)表了第一篇關(guān)于漢字識(shí)別的文章,采用了模板匹配法識(shí)別了1000個(gè)印刷體漢字。
早在60、70年代,世界各國就開始有OCR的研究,而研究的初期,多以文字的識(shí)別方法研究為主,且識(shí)別的文字僅為0至9的數(shù)字。以同樣擁有方塊文字的日本為例,1960年左右開始研究OCR的基本識(shí)別理論,初期以數(shù)字為對(duì)象,直至1965至1970年之間開始有一些簡單的產(chǎn)品,如印刷文字的郵政編碼識(shí)別系統(tǒng),識(shí)別郵件上的郵政編碼,幫助郵局作區(qū)域分信的作業(yè);也因此至今郵政編碼一直是各國所倡導(dǎo)的地址書寫方式。
20世紀(jì)70年代初,日本的學(xué)者開始研究漢字識(shí)別,并做了大量的工作。中國在OCR技術(shù)方面的研究工作起步較晚,在70年代才開始對(duì)數(shù)字、英文字母及符號(hào)的識(shí)別進(jìn)行研究,70年代末開始進(jìn)行漢字識(shí)別的研究,到1986年漢字識(shí)別的研究進(jìn)入一個(gè)實(shí)質(zhì)性的階段,不少研究單位相繼推出了中文OCR產(chǎn)品.早期的OCR軟件,由于識(shí)別率及產(chǎn)品化等多方面的因素,未能達(dá)到實(shí)際要求。同時(shí),由于硬件設(shè)備成本高,運(yùn)行速度慢,也沒有達(dá)到實(shí)用的程度。只有個(gè)別部門,如信息部門、新聞出版單位等使用OCR軟件。1986年以后我國的OCR研究有了很大進(jìn)展,在漢字建模和識(shí)別方法上都有所創(chuàng)新,在系統(tǒng)研制和開發(fā)應(yīng)用中都取得了豐碩的成果,不少單位相繼推出了中文OCR產(chǎn)品。進(jìn)入20世紀(jì)90年代以后,隨著平臺(tái)式掃描儀的廣泛應(yīng)用,以及我國信息自動(dòng)化和辦公自動(dòng)化的普及,大大推動(dòng)了OCR技術(shù)的進(jìn)一步發(fā)展,使OCR的識(shí)別正確率、識(shí)別速度滿足了廣大用戶的要求。[1]
編輯本段軟件結(jié)構(gòu)由于掃描儀的普及與廣泛應(yīng)用,OCR軟件只需提供與掃描儀的接口,利用掃描儀驅(qū)動(dòng)軟件即可。因此,OCR軟件主要是由下面幾個(gè)部分組成。
圖像輸入、預(yù)處理:
圖像輸入:對(duì)于不同的圖像格式,有著不同的存儲(chǔ)格式,不同的壓縮方式,目前有,等開源項(xiàng)目 。預(yù)處理:主要包括二值化,噪聲去除,傾斜較正等
二值化:
對(duì)攝像頭拍攝的圖片,大多數(shù)是彩色圖像,彩色圖像所含信息量巨大,對(duì)于圖片的內(nèi)容,我們可以簡單的分為前景與背景,為了讓計(jì)算機(jī)更快的,更好的識(shí)別文字,我們需要先對(duì)彩色圖進(jìn)行處理,使圖片只前景信息與背景信息,可以簡單的定義前景信息為黑色,背景信息為白色,這就是二值化圖了。

噪聲去除:
對(duì)于不同的文檔,我們對(duì)燥聲的定義可以不同,根據(jù)燥聲的特征進(jìn)行去燥,就叫做噪聲去除
傾斜較正:
由于一般用戶,在拍照文檔時(shí),都比較隨意,因此拍照出來的圖片不可避免的產(chǎn)生傾斜,這就需要文字識(shí)別軟件進(jìn)行較正。
版面分析:
將文檔圖片分段落尚書7號(hào)ocr文字識(shí)別系統(tǒng)完全版 注冊(cè)碼,分行的過程就叫做版面分析,由于實(shí)際文檔的多樣性,復(fù)雜性,因此,目前還沒有一個(gè)固定的,最優(yōu)的切割模型。
字符切割:
由于拍照條件的限制,經(jīng)常造成字符粘連,斷筆,因此極大限制了識(shí)別系統(tǒng)的性能,這就需要文字識(shí)別軟件有字符切割功能。
字符識(shí)別:
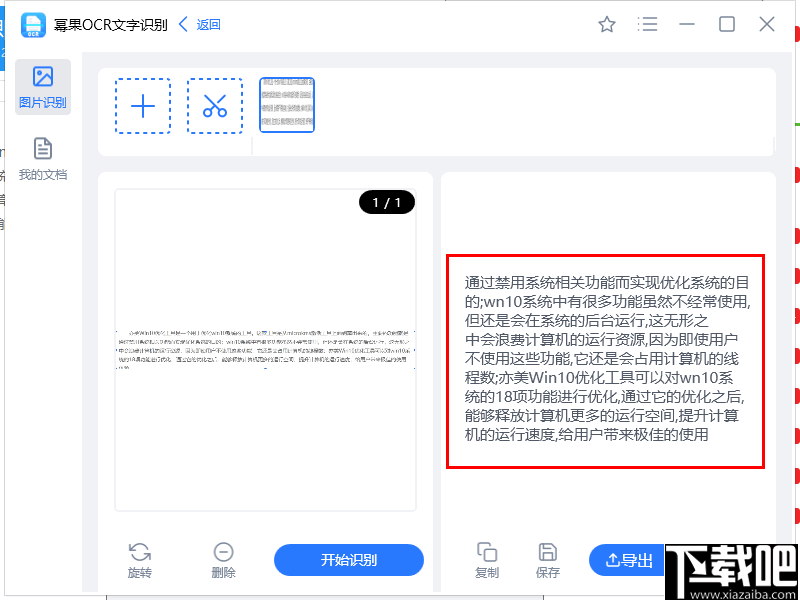
這一研究,已經(jīng)是很早的事情了,比較早有模板匹配,后來以特征提取為主,由于文字的位移,筆畫的粗細(xì),斷筆,粘連,旋轉(zhuǎn)等因素的影響,極大影響特征的提取的難度。
版面恢復(fù):
人們希望識(shí)別后的文字,仍然像原文檔圖片那樣排列著,段落不變,位置不變,順序不變,的輸出到word文檔,pdf文檔等,這一過程就叫做版面恢復(fù)。
后處理、校對(duì):
根據(jù)特定的語言上下文的關(guān)系,對(duì)識(shí)別結(jié)果進(jìn)行較正,就是后處理。
編輯本段工作流程一個(gè)OCR識(shí)別系統(tǒng),其目的很簡單,只是要把影像作一個(gè)轉(zhuǎn)換,使影像內(nèi)的圖形繼續(xù)保存、有表格則表格內(nèi)資料及影像內(nèi)的文字,一律變成計(jì)算機(jī)文字,使能達(dá)到影像資料的儲(chǔ)存量減少、識(shí)別出的文字可再使用及分析,當(dāng)然也可節(jié)省因鍵盤輸入的人力與時(shí)間。
從影像到結(jié)果輸出,須經(jīng)過影像輸入、影像前處理、文字特征抽取、比對(duì)識(shí)別、最后經(jīng)人工校正將認(rèn)錯(cuò)的文字更正,將結(jié)果輸出。
影像輸入
欲經(jīng)過OCR處理的標(biāo)的物須透過光學(xué)儀器,如影像掃描儀、傳真機(jī)或任何攝影器材,將影像轉(zhuǎn)入計(jì)算機(jī)。科技的進(jìn)步,掃描儀等的輸入裝置已制作的愈來愈精致,輕薄短小、品質(zhì)也高,對(duì)OCR有相當(dāng)大的幫助,掃描儀的分辨率使影像更清晰、掃除速度更增進(jìn)OCR處理的效率。

影像前處理:影像前處理是OCR系統(tǒng)中,須解決問題最多的一個(gè)模塊,從得到一個(gè)不是黑就是白的二值化影像,或灰階、彩色的影像,到獨(dú)立出一個(gè)個(gè)的文字影像的過程,都屬于影像前處理。包含了影像正規(guī)化、去除噪聲、影像矯正等的影像處理,及圖文分析、文字行與字分離的文件前處理。在影像處理方面,在學(xué)理及技術(shù)方面都已達(dá)成熟階段,因此在市面上或網(wǎng)站上有不少可用的鏈接庫;在文件前處理方面,則憑各家本領(lǐng)了;影像須先將圖片、表格及文字區(qū)域分離出來,甚至可將文章的編排方向、文章的提綱及內(nèi)容主體區(qū)分開,而文字的大小及文字的字體亦可如原始文件一樣的判斷出來。
文字特征抽取:單以識(shí)別率而言,特征抽取可說是 OCR的核心,用什么特征、怎么抽取,直接影響識(shí)別的好壞,也所以在OCR研究初期,特征抽取的研究報(bào)告特別的多。而特征可說是識(shí)別的籌碼,簡易的區(qū)分可分為兩類:一為統(tǒng)計(jì)的特征,如文字區(qū)域內(nèi)的黑/白點(diǎn)數(shù)比,當(dāng)文字區(qū)分成好幾個(gè)區(qū)域時(shí),這一個(gè)個(gè)區(qū)域黑/白點(diǎn)數(shù)比之聯(lián)合,就成了空間的一個(gè)數(shù)值向量,在比對(duì)時(shí),基本的數(shù)學(xué)理論就足以應(yīng)付了。而另一類特征為結(jié)構(gòu)的特征,如文字影像細(xì)線化后,取得字的筆劃端點(diǎn)、交叉點(diǎn)之?dāng)?shù)量及位置,或以筆劃段為特征,配合特殊的比對(duì)方法,進(jìn)行比對(duì),市面上的線上手寫輸入軟件的識(shí)別方法多以此種結(jié)構(gòu)的方法為主。
對(duì)比數(shù)據(jù)庫:當(dāng)輸入文字算完特征后,不管是用統(tǒng)計(jì)或結(jié)構(gòu)的特征,都須有一比對(duì)數(shù)據(jù)庫或特征數(shù)據(jù)庫來進(jìn)行比對(duì),數(shù)據(jù)庫的內(nèi)容應(yīng)包含所有欲識(shí)別的字集文字,根據(jù)與輸入文字一樣的特征抽取方法所得的特征群組。
對(duì)比識(shí)別
這是可充分發(fā)揮數(shù)學(xué)運(yùn)算理論的一個(gè)模塊,根據(jù)不同的特征特性,選用不同的數(shù)學(xué)距離函數(shù),較有名的比對(duì)方法有,歐式空間的比對(duì)方法、松弛比對(duì)法()、動(dòng)態(tài)程序比對(duì)法( ,DP),以及類神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)庫建立及比對(duì)、HMM( Model)…等著名的方法,為了使識(shí)別的結(jié)果更穩(wěn)定,也有所謂的專家系統(tǒng)( )被提出,利用各種特征比對(duì)方法的相異互補(bǔ)性,使識(shí)別出的結(jié)果,其信心度特別的高。
字詞后處理:由于OCR的識(shí)別率并無法達(dá)到百分之百,或想加強(qiáng)比對(duì)的正確性及信心值,一些除錯(cuò)或甚至幫忙更正的功能,也成為OCR系統(tǒng)中必要的一個(gè)模塊。字詞后處理就是一例,利用比對(duì)后的識(shí)別文字與其可能的相似候選字群中,根據(jù)前后的識(shí)別文字找出最合乎邏輯的詞,做更正的功能。
字詞數(shù)據(jù)庫:為字詞后處理所建立的詞庫。
人工校正
OCR最后的關(guān)卡,在此之前,使用者可能只是拿支鼠標(biāo),跟著軟件設(shè)計(jì)的節(jié)奏操作或僅是觀看,而在此有可能須特別花使用者的精神及時(shí)間,去更正甚至找尋可能是OCR出錯(cuò)的地方。一個(gè)好的OCR軟件,除了有一個(gè)穩(wěn)定的影像處理及識(shí)別核心,以降低錯(cuò)誤率外,人工校正的操作流程及其功能,亦影響OCR的處理效率,因此,文字影像與識(shí)別文字的對(duì)照,及其屏幕信息擺放的位置、還有每一識(shí)別文字的候選字功能、拒認(rèn)字的功能、及字詞后處理后特意標(biāo)示出可能有問題的字詞,都是為使用者設(shè)計(jì)盡量少使用鍵盤的一種功能,當(dāng)然,不是說系統(tǒng)沒顯示出的文字就一定正確尚書7號(hào)ocr文字識(shí)別系統(tǒng)完全版 注冊(cè)碼,就像完全由鍵盤輸入的工作人員也會(huì)有出錯(cuò)的時(shí)候,這時(shí)要重新校正一次或能允許些許的錯(cuò),就完全看使用單位的需求了。

結(jié)果輸出
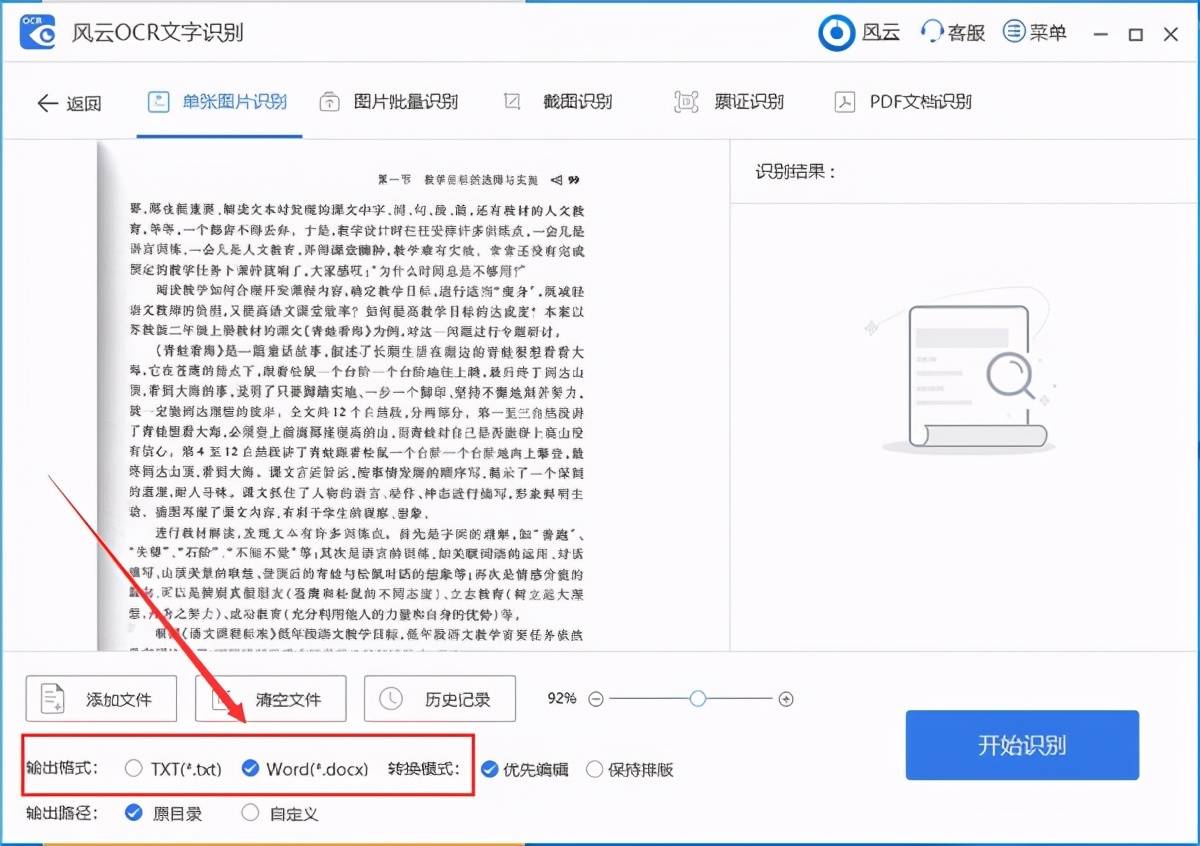
有人只要文本文件作部份文字的再使用之用,所以只要一般的文字文件、有人要漂漂亮亮的和輸入文件一模一樣,所以有原文重現(xiàn)的功能、有人注重表格內(nèi)的文字,所以要和Excel等軟件結(jié)合。無論怎么變化,都只是輸出檔案格式的變化而已。如果需要還原成原文一樣格式,則在識(shí)別后,需要人工排版,耗時(shí)耗力。
編輯本段中文識(shí)別資料錄入
文獻(xiàn)資料的數(shù)字化錄入,一般分為:
1.純圖像方式。
2.目錄文本、正文圖像方式。
3.全文本方式。
4.全文索引方式。文本方式和圖像方式的混合體。
識(shí)別過程
書本級(jí):中文,英文;簡體,繁體;
版式級(jí):豎排,橫排;有無分欄;
行切分字切分
識(shí)別:真正的OCR識(shí)別過程,圖像信息還原成文本信息
后處理:人工干預(yù),主要集中在前四個(gè)階段。
識(shí)別結(jié)果決定因素
1.圖片的質(zhì)量,一般建議以上
2.顏色,一般對(duì)彩色識(shí)別很差,黑白的圖片較高,因此建議ocr的為黑白tif格式
3.最重要的就是字體,如果是手寫識(shí)別率很低。
國內(nèi)OCR識(shí)別簡體差錯(cuò)率為萬分之三,如果要求更高的精度需要投入更大的人工干預(yù)。繁體識(shí)別由于繁體字庫的不統(tǒng)一性(民國時(shí)期的字庫和現(xiàn)在繁體字庫不統(tǒng)一),導(dǎo)致識(shí)別困難,在人工干預(yù)下,精度能達(dá)到90%以上(圖文清晰情況下)。
編輯本段識(shí)別技巧1.分辨率的設(shè)置是文字識(shí)別的重要前提。一般來講,掃描儀提供較多的圖像信息,識(shí)別軟件比較容易得出識(shí)別結(jié)果。但也不是掃描分辨率設(shè)得越高識(shí)別正確率就越高。選擇或分辨率,適合大部分文檔掃描。注意文字原稿的掃描識(shí)別,設(shè)置掃描分辨率時(shí)千萬不要超過掃描儀的光學(xué)分辨率,不然會(huì)得不償失。下面是部分典型設(shè)置,僅供參考。