

在前面一篇文章中提到過對于業務主表讀寫緩慢的解決方案:冷熱分離復雜查詢 內存數據庫,有不了解的請看:業務主表讀寫緩慢如何優化?
冷熱分離固然是一個性價比高的解決方案,但也并不是銀彈,仍然有諸多限制,比如:
查詢冷數據慢業務無法修改冷數據冷數據多到一定程度系統依舊扛不住
此時如果需要解決以上問題,可以采用另外一種方案:使用 查詢分離 優化業務主表數據大查詢緩慢的問題
什么是查詢分離?
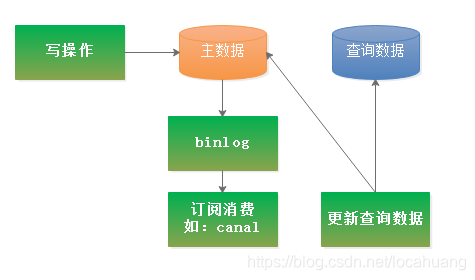
查詢分離從字面上來說非常容易理解,其實就是在寫數據時保存一個備份數據到另外的存儲系統,在查詢時直接從另外的存儲系統中獲取數據,如下圖:
查詢分離
以上只是簡單的架構圖,其中有些細節還是需要深究,如下:
什么時候觸發查詢分離?如何實現查詢分離?查詢數據的存儲系統選型?查詢數據如何使用?查詢分離的適用場景?
當你在實際業務中遇到以下情形,則可以考慮使用查詢分離解決方案。
曾做過 SaaS 客服系統的架構優化,系統里有一個工單查詢功能,工單表中存放了幾千萬條數據,且查詢工單表數據時需要關聯十幾個子表,每個子表的數據也是超億條。

面對如此龐大的數據量,跟前面的冷熱分離一樣,每次客戶查詢數據時幾十秒才能返回結果,即便我們使用了索引、SQL 等數據庫優化技巧,效果依然不明顯。
工單表中有些數據是幾年前的,客戶說這些數據涉及訴訟問題,需要繼續保持更新,因此我們無法將這些舊數據封存到別的地方,也就沒法通過前面的冷熱分離方案來解決。
最終我們采用了查詢分離的解決方案,才得以將這個問題順利解決:將更新的數據放在一個數據庫里,而查詢的數據放在另外一個系統里。因為數據的更新都是單表更新,不需要關聯也沒有外鍵,所以更新速度立馬得到提升,每次客戶查詢數據時,500ms 內就可得到返回結果。
什么時候觸發查詢分離?
簡單的來說就是什么時候應該保存一份數據到查詢數據庫中,其實也就是數據異構的過程,詳細文章可以看我前面一篇文章:數據異構就該這樣做,yyds~
這里介紹三種方式,如下:
同步建立異步建立方式1、 同步建立
修改業務代碼:在寫入常規數據后,同步建立查詢數據。
該種方案優缺點也非常明顯:
優點:查詢數據的一致性和實時性得到了保證
缺點:業務代碼侵入比較強;減緩寫操作的效率
2、 異步建立
修改業務代碼:寫入數據后,異步建立查詢數據
該種方案的優缺點如下:
優點:不影響主流程
缺點:數據一致性存在問題
3、 的方式
該種方案也是業界常用的一種方案,對于代碼是無侵入的,通過監聽數據庫日志的方式建立查詢數據,如下:

該種方案的優缺點如下:
優點:不影響主流程;代碼侵入為0
缺點:數據一致性存在問題;架構相對復雜
如何實現查詢分離?
對于上述三種方案都算是比較常見的方案,對于第一種同步的方式比較簡單,這里不再介紹;對于第三種的方式在數據異構的文章中介紹過,詳情見:數據異構就該這樣做,yyds~
這篇文章來介紹一下異步的方式,異步的方式有很多,可以放在內存中進行操作,但是這有些弊端:
數據過多,內存有限服務重啟,內存數據將會丟失
因此最終我們可以選擇MQ的方式,那么此時就涉及到了MQ的技術選型,這里給兩個建議:
如果你的公司已經用了MQ,那么直接接著用即可如果公司目前未引入MQ,則需要架構組考量選型了,對于MQ的選型可以看我之前文章:聊聊 MQ 技術選型

當然一旦引入了MQ還需要考慮的問題很多,如下:
1、 MQ突然宕機了怎么辦?
MQ宕機意味著查詢數據不能繼續建立了,我們可以在寫入數據的同時給該條數據加一個標志字段(已搬運、未搬運),當MQ啟動后,查詢所有未搬運的數據,繼續建立查詢數據
“
這里的方案很多,按照業務實際情況考量
”
2、消息的冪等消費
消息的冪等消費一定要保證,避免數據重復建立,比如:主數據的訂單 A 更新后,我們在查詢數據中插入了 A,可是此時系統出問題了,系統誤以為查詢數據沒更新,又把訂單 A 插入更新了一次。
3、消息的時序性問題
比如某個訂單 A 更新了 1 次數據變成 A1,線程甲將 A1 的數據搬到查詢數據中。不一會兒,后臺訂單 A 又更新了 1 次數據變成 A2,線程乙也啟動工作,將 A2 的數據搬到查詢數據中。

所謂的時序性就是如果線程甲啟動比乙早,但搬運數據動作比線程乙還晚完成,就有可能出現查詢數據最終變成過期的 A1
查詢數據的存儲系統選型?
既然為了解決表數據量大查詢緩慢的問題,肯定是不能選用關系型數據庫了,那么還有其他選擇嗎?
內存數據庫雖然性能非常高,比如Redis,但是不適合海量數據,太費錢了
那么這里比較適用的有如下三種:
earch
這里選型還是要根據自己公司業務選擇,如果已經有在用的,則直接用即可;另外就是選擇自己熟悉的,比如當初我們設計架構方案時,為什么選擇用 ,除 ES 對查詢的擴展性支持外,最關鍵的一點是我們團隊對 很熟悉。
查詢數據如何使用?
查詢數據很簡單,每個數據庫都有對應的API,直接調用查詢
但是,這里有一個問題:數據查詢更新完前,查詢數據不一致怎么辦?,給出兩種方案:
在查詢數據更新到最新前,不允許用戶查詢。(我們沒用過這種設計,但我確實見過市面上有這樣的設計。)給用戶提示:您目前查詢到的數據可能是 1 秒前的數據,如果發現數據不準確,可以嘗試刷新一下,這種提示用戶一般比較容易接受。總結
本篇文章介紹了表數據量大查詢緩慢的一種解決方案:查詢分離復雜查詢 內存數據庫,但這也不是銀彈,仍然是存在一些不足,比如表數據量大,寫入緩慢怎么辦?這個后面文章再介紹吧
當然查詢分離還有一個重要的問題:歷史數據如何遷移?這個處理也是非常簡單,但是也有許多需要考慮的點,后文介紹